
OpenAI 放开成人内容?体验新版 GPT-4o 后,我想再次感谢 DeepSeek
OpenAI 放开成人内容?体验新版 GPT-4o 后,我想再次感谢 DeepSeekSam Altman 又当了一回谜语人。2 月 16 日,他宣布更新了我们的老朋友 GPT-4o,却没说细节。
来自主题: AI资讯
9305 点击 2025-02-19 15:03
 搜索
搜索
Sam Altman 又当了一回谜语人。2 月 16 日,他宣布更新了我们的老朋友 GPT-4o,却没说细节。
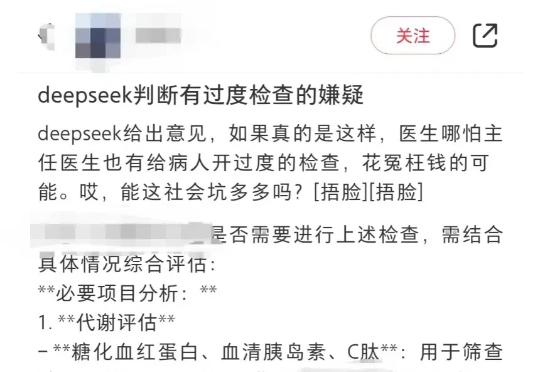
「医生,你开的这些检查都没有必要,属于『过度检查』。」「谁说没有必要?」「DeepSeek 说的。」最近,有位家属在社交平台上发文表示,孩子在医院接受的部分检查被 DeepSeek 判断为「可能非必要」,于是这位家属认为接诊的医生是在「开过度的检查」,让人「花冤枉钱」。
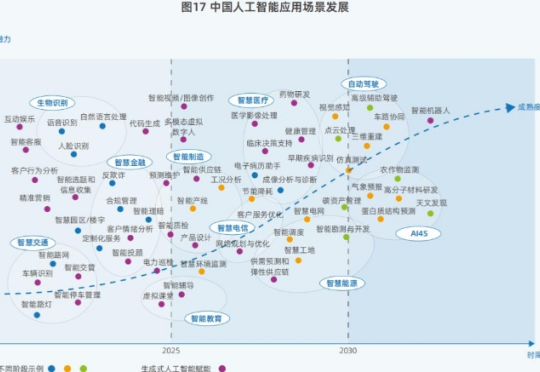
这个AI领域千亿级市场,将辐射千家万户。 DeepSeek-R1横空出世,打响了大模型比拼性价比的第一枪。 Meta、OpenAI等国外头部大模型厂商纷纷复刻或变相降价。比DeepSeek-R1晚两周发布的OpenAI o3-mini模型,定价比前代模型o1-mini降低了超6成,比前代完整版的o1模型便宜超9成。

“我十分想见梁文锋。” DeepSeek火了之后,投资圈开始焦虑了。 根据“路边消息社”报道,“最近想要见DeepSeek创始人梁文锋,需要汇报到地方办公室。”根据报道,最近想要约见梁文锋的投资机构太多,为了保护这位AI大牛,想约见他的机构,需要先报到省委办公厅。

大模型混战,一边卷能力,一边卷“低价”。 DeepSeek彻底让全球都坐不住了。 昨天,马斯克携“地球上最聪明的AI”——Gork 3在直播中亮相,自称其“推理能力超越目前所有已知模型”,在推理-测试时间得分上,也好于DeepSeek R1、OpenAI o1。不久前,国民级应用微信宣布接入DeepSeek R1,正在灰度测试中,这一王炸组合被外界认为AI搜索领域要变天。

当 DeepSeek 在春节期间爆火,所有人都在猜测国内 AI 厂商将会如何跟进时,腾讯元宝上周宣布接入满血版 DeepSeek R1,APPSO 体验后彻底告别了「服务器繁忙」。而就在刚刚,腾讯元宝正式推出自研的 Hunyuan T1 快速深度思考模型,给了我们两种深度思考模型的选择,APPSO 也提前体验了这款模型,第一时间给大家送上使用指南。

应用内接入 DeepSeek-R1 已经成了一种潮流。
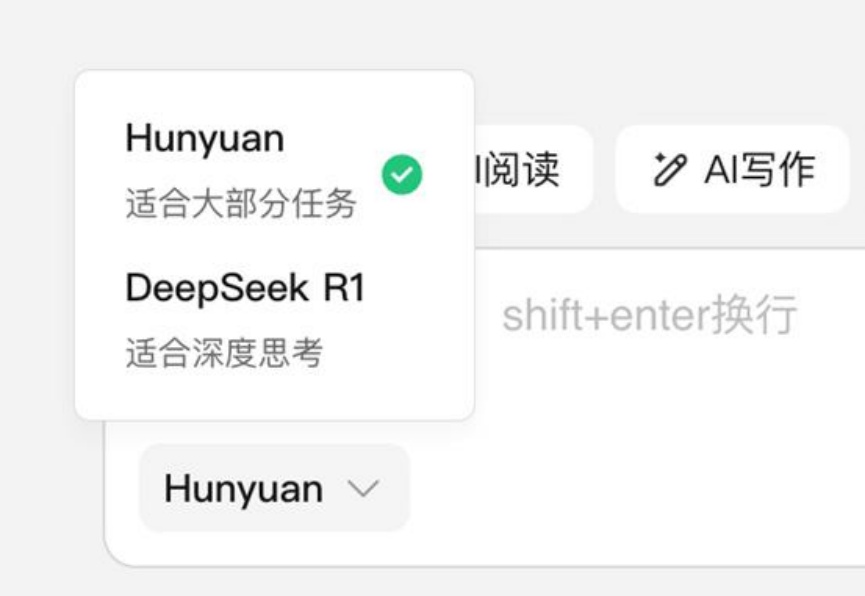
接入DeepSeek,不等于All in DeepSeek
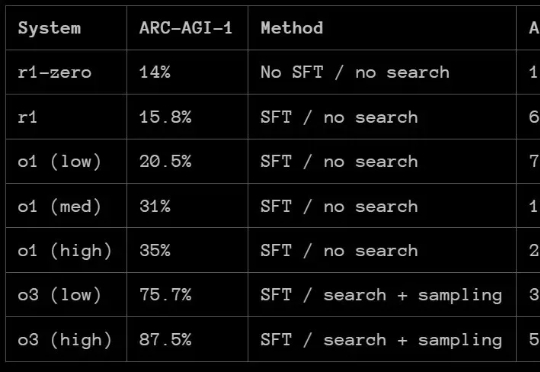
那么,DeepSeek-R1 的 ARC-AGI 成绩如何呢?根据 ARC Prize 发布的报告,R1 在 ARC-AGI-1 上的表现还赶不上 OpenAI 的 o1 系列模型,更别说 o3 系列了。但 DeepSeek-R1 也有自己的特有优势:成本低。

DeepSeek团队最新力作一上线,就获得Ai2研究所大牛推荐,和DeepSeek铁粉们的热情研读!他们提出的CodeI/O全新方法,通过代码提取了LLM推理模式,在逻辑、数学等推理任务上得到显著改进。